
BY ANDREY SHALITKIN - FREELANCE SOFTWARE ENGINEER
@ TOPTAL(TRANSLATED BY MARISELA ORDAZ)
Link original de la publicación: Aquí
Hay muchas discusiones, artículos y blogs que tratan el tema de calidad de código. La gente dice – ¡usa técnicas Test Driven! ¡Los testeos son algo que “debes tener” para comenzar cualquier refactorización! Todo eso está bien, pero estamos en el 2016 y hay una gran cantidad de productos y bases de código que todavía están en producción, los cuales fueron creados hace diez, quince y hasta veinte años. No es secreto que muchos de ellos tienen código heredado con baja cobertura de prueba.
Aunque siempre me gustaría estar en el borde principal, o hasta sangriento, del mundo tecnológico – comprometido con nuevos proyectos y tecnologías – desafortunadamente no siempre es posible y a menudo tengo que lidiar con sistemas obsoletos. Me gusta decir que cuando desarrollas desde cero, actúas como creador, creando nueva materia. Pero cuando trabajas con código heredado, eres como un cirujano – sabes cómo funciona el sistema en general pero nunca sabes con seguridad si el paciente saldrá bien de la “operación”. Y ya que es un código heredado, no hay muchos testeos actualizadas en las que puedas confiar. Esto quiere decir que, frecuentemente, uno de los primeros pasos es cubrirlo con testeos. Para ser más precisos, no sólo para proporcionar cobertura sino para desarrollar una estrategia de prueba de cobertura.

Básicamente, lo que necesitaba determinar era que partes (clases / paquetes) del sistema necesitábamos cubrir con testeos en primer lugar, dónde necesitamos testeos de unidad, dónde serían más útiles testeos de interrogación, etc. Hay muchas formas de abordar este tipo de análisis y el que he usado tal vez no sea el mejor, pero es parecido a un acercamiento automático. Una vez que se ha implementado mi acercamiento, toma poco tiempo hacer el análisis como tal y lo que es más importante, trae algo de diversión al análisis de código heredado.
La idea principal aquí es analizar dos métricas – acoplamiento (ej., acoplamiento aferente, o CA) y complejidad (ej. Complejidad ciclomática).
La primera mide cuántas clases mide nuestra clase, así que básicamente nos dice que tan cerca está alguna clase en particular al corazón del sistema; mientras más clases hay que usan nuestra clase, más importante es cubrirlas con testeos.
Por otra parte, si una clase es muy simple (ej. Contiene sólo constantes), entonces si es usada por muchas otras partes del sistema, no es tan importante crear una prueba para ella. Aquí es donde la segunda métrica puede ayudar. Si una clase contiene mucha lógica, la complejidad Ciclomática será alta.
La misma lógica puede ser aplicada en reversa; ej., aún si una clase no es usada por muchas clases y representa solo un caso de uso particular, todavía tiene sentido cubrirla con testeos si su uso interno lógico es complejo.
Sin embargo, hay una advertencia: digamos que tenemos dos clases – una con CA de 100 y complejidad de 2, y la otra con CA de 60 y complejidad de 20. Aunque la suma de las métricas es más alta para la primera, deberíamos cubrir la segunda primero. Esto se da porque la primera clase está siendo usada por muchas otras clases, pero no es muy compleja. Por otro lado, la segunda clase también está siendo usada por muchas otras clases pero es relativamente más compleja que la primera clase.
Para resumir: necesitamos identificar las clases con CA alto y complejidad Ciclomática. En términos matemáticos, se necesita una función fitness que pueda ser usada como clasificación. - f(CA,Complejidad) – de la cual los valores aumentan junto con CA y Complejidad.
En general, las clases con las diferencias más pequeñas entre las dos métricas deberían tener la prioridad más alta para cobertura de prueba.
Encontrar herramientas para calcular CA y Complejidad para toda la base de código y proporcionar una manera simple de extraer esta información en formato CSV, demostró ser un reto. Durante mi búsqueda, encontré dos herramientas que son gratis entonces sería injusto no mencionarlas:
- Acoplando métricas: www.spinellis.gr/sw/ckjm/
- Complejidad: cyvis.sourceforge.net/
Un Poco De Matemáticas
El problema principal aquí es que tenemos dos criterios – CA y complejidad Ciclomática – por esto necesitamos combinarlas y convertirlas en un solo valor escalar. Si tuviéramos una tarea un poco diferente – ej., encontrar una clase con la peor combinación de nuestros criterios – tendríamos un problema clásico de optimización multiobjetiva:
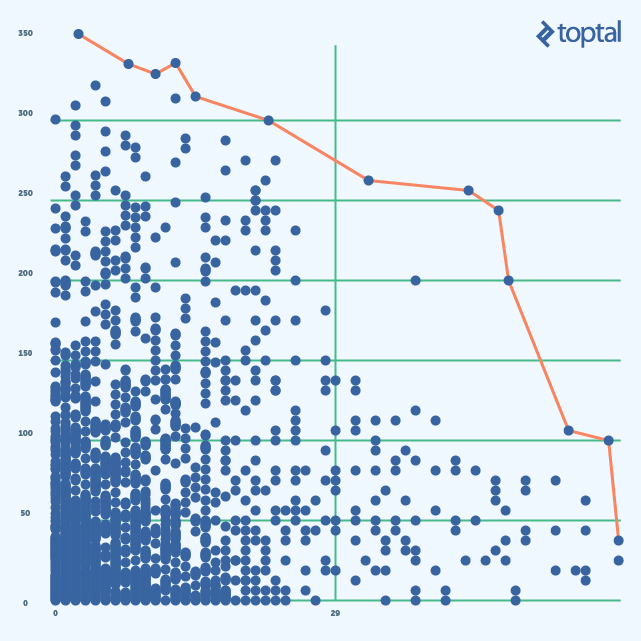
Necesitamos encontrar un punto en el llamado frente de Pareto (rojo en la foto de arriba). Lo interesante sobre el set Pareto es que cada punto en el set es una solución para la prueba de optimización. Cada vez que avanzamos por la línea roja, necesitamos comprometernos con nuestros criterios – si uno mejora el otro empeora. Esto se llama Escalarización y el resultado final depende de cómo se realice.
Hay muchas técnicas que podemos usar aquí. Cada una tiene sus pros y sus contras. Sin embargo, las más populares son escalarización lineal y el que se basa en un punto de referencia. La lineal es la más fácil. Nuestra función fitness se verá como una combinación lineal de CA y Complejidad:
f(CA, Complexity) = A×CA + B×Complexity
donde A y B son algunos coeficientes.
El punto que representa una solución para nuestro problema de optimización está en la línea (azul en la foto debajo). Precisamente, será la intersección de la línea azul y el frente rojo de Pareto. Nuestro problema original no es exactamente un problema de optimización. Pero necesitamos crear una función de categorización. Consideremos dos valores de nuestra función de categorización, básicamente dos valores en nuestra columna Rango.
R1 = A∗CA + B∗Complexity and R2 = A∗CA + B∗Complexity
Algunas de las fórmulas escritas arriba son ecuaciones de líneas, más aún estas líneas son paralelas. Tomando más valores de categorización en consideración tendremos más líneas y por esto más puntos donde intersecta la línea Pareto con las líneas azules (punteadas). Estos puntos serán clases correspondientes a un valor categorizado particular.
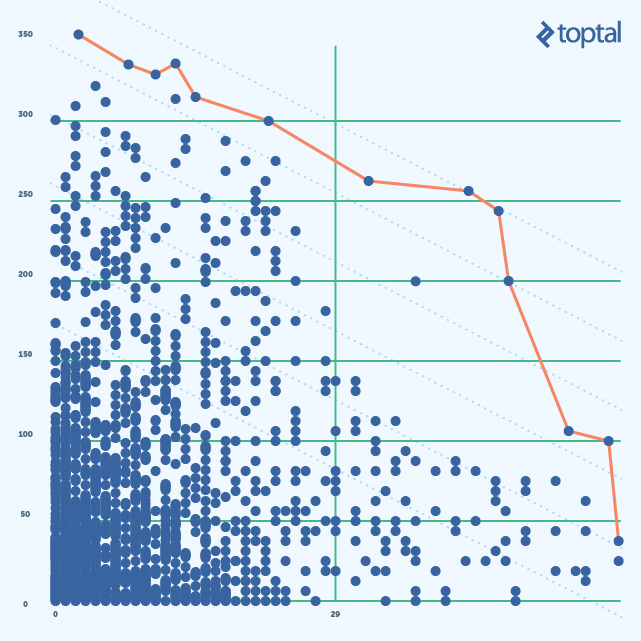
Desafortunadamente, hay un problema con este acercamiento. Para cualquier línea (Valor Categorizado), tendremos puntos con pequeños CA y muy grande Complejidad (y viceversa) en ella. Esto inmediatamente pone puntos con una gran diferencia entre valores de métrica de primero en la lista, que exactamente lo que queríamos evitar.
La otra manera de hacer la escalarización está basada en el punto de referencia. El punto de referencia es un punto con los valores máximos de ambos criterios:
(max(CA), max(Complexity))
La función fitness será la distancia entre el punto de Referencia y los puntos de data:
f(CA,Complexity) = √((CA−CA )2 + (Complexity−Complexity)2)
Podemos pensar en esta función fitness como un círculo con el centro en el punto de Referencia. El radio en este caso es el valor de la categorización. La solución para el problema de optimización será el punto donde el círculo toca el frente Pareto. La solución al problema original será sets de puntos correspondientes a los distintos radios de círculo como se muestran en la siguiente imagen (partes de círculos para diferentes categorías se muestran como curvas punteadas azules):
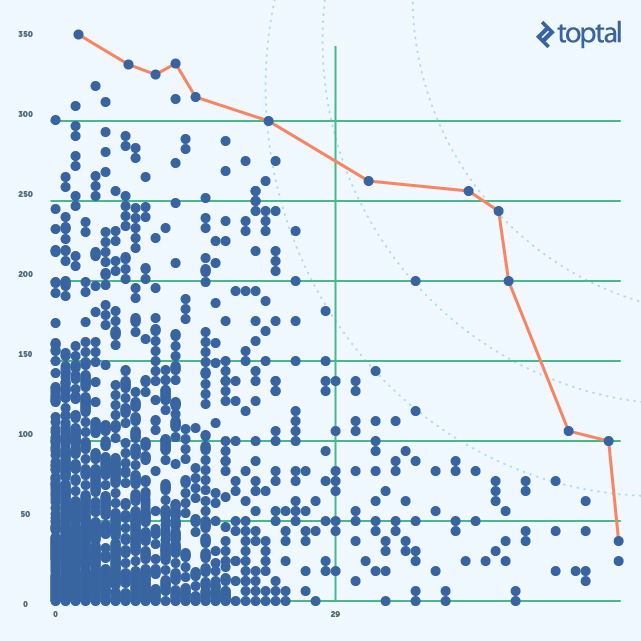
Este acercamiento maneja mejor valores extremos, pero todavía hay dos problemas: Primero – me gustaría tener más puntos cerca de los puntos de referencia para solventar mejor el problema que hemos enfrentado con combinación lineal. Segundo – CA y complejidad Ciclomática son inherentemente diferentes y tienen set de valores diferentes, así que necesitamos normalizarlos (ej. Para que todos los valores de ambas métricas sean de 1 a 100)
Aquí hay un pequeño truco que podemos aplicar para solventar el primer problema – en vez de mirar al CA y a la complejidad ciclomática, podemos mirar sus valores invertidos. El punto de referencia en este caso será (0,0). Para solucionar el segundo problema, podemos normalizar las métricas usando un valor mínimo. Aquí está cómo se ve:
Complejidad normalizada e invertida – NormComplexity:
(1 + min(Complexity)) / (1 + Complexity)∗100
CA invertida y normalizada – NormCA:
(1 + min(CA)) / (1+CA)∗100
Nota: Agregué 1 para asegurarme de que no haya división por 0. t
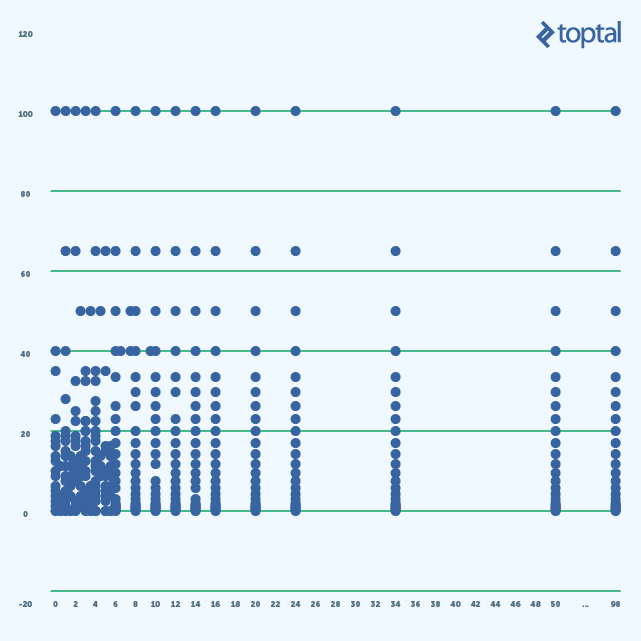
La siguiente imagen muestra un gráfico con valores invertidos:
Categorización Final
Llegamos al paso final – calcular la categorización. Como mencione, estoy usando el método de punto de referencia, así que lo único que necesitamos hacer es calcular el largo del vector, normalizarlo y hacerlo ascender con la importancia de la creación de una prueba de unidad para una clase. Aquí está la última fórmula:
Rank(NormComplexity , NormCA) = 100 − √(NormComplexity2 + NormCA2) / √2
Más Estadísticas
Hay más pensamientos que me gustaría agregar, pero primero miremos algunas estadísticas. Aquí está un histograma de las métricas acopladoras:
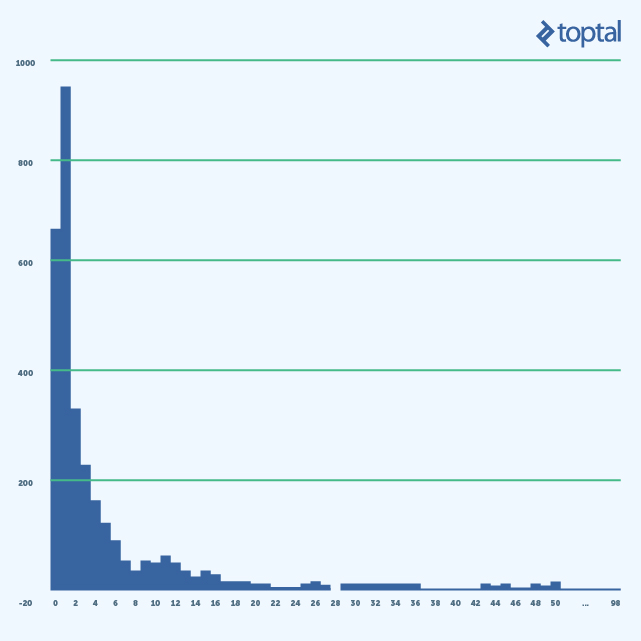
Lo interesante de esta imagen es el número de clases con baja CA (0-2). Clases con CA en 0 no se usan para nada o son servicios de alto nivel. Estas representan puntos finales API, así que está bien si tenemos muchos de ellos. Pero las clases con CA en 1 son las que están directamente usadas por los puntos finales y tenemos más de estas clases que puntos finales. ¿Qué significa esto desde la perspectiva de arquitectura/diseño?
En general, significa que tenemos un acercamiento orientado al guion – hacemos un guión para cada caso de negocios por separado (no podemos reutilizar el código ya los casos de negocios son muy diversos). Si ese es el caso, entonces es definitivamente un código olor y necesitamos refactorizar. Sino, significa que la cohesión de nuestro sistema es baja, en este caso también necesitamos refactorizar, pero refactorización de arquitectura en este caso.
La información adicional que podemos obtener del histograma de arriba es que podemos filtrar completamente clases con bajo acoplamiento (CA en {0,1}) de la lista de las clases disponibles para cobertura con testeos de unidad. Las mismas clases, sin embargo, son buenas candidatas para los testeos de integración/funcional.
Puedes encontrar todos los guiones y recursos que usé en este repositorio GitHub: ashalitkin/code-base-stats.
¿Siempre funciona?
No necesariamente. Primero que todo, todo se trata del análisis estático, no tiempo de ejecución. Si una clase se filtra desde muchas otras clases, puede ser una señal de que es muy usada, pero no siempre es así. Por ejemplo, no sabemos si la funcionalidad es usada fuertemente por usuarios finales. Segundo, si el diseño y la calidad del sistema es lo suficientemente bueno, seguramente diferentes partes/capas de éste están desacoplados a través de las interfaces, así que un análisis estático de CA no nos dará una imagen verdadera. Supongo que es una de las razones principales porque CA no es una herramienta popular como Sonar. Afortunadamente, está bien para nosotros ya que, si recuerdas, nos interesa aplicar esto específicamente a bases de código viejas y feas.
En general, yo diría que el análisis de tiempo de ejecución daría mejores resultados pero, desafortunadamente, es mucho más costoso, consume más tiempo y es complejo, así que nuestro acercamiento es potencialmente una alternativa útil y menos costosa.

No hay comentarios:
Publicar un comentario
Te agradezco tus comentarios. Te esperamos de vuelta.