
This article was originally written in English
Link original de este artículo: https://www.toptal.com/ruby-on-rails/construye-elegantes-componentes-rails-con-plain-old-ruby-objects/es
Tu
sitio web está avanzando y estás creciendo rápidamente. Ruby/Rails es
tu mejor opción de programación. Tu equipo es más grande y ya dejaste el
concepto “modelos gordos, controladores delgados” (fat models, skinny controllers) como estilo de diseño para tus aplicaciones Rails. Sin embargo, todavía no quieres dejar de usar Rails.
No hay problema. Hoy vamos a discutir cómo usar las mejores prácticas POO para hacer tu código más limpio, aislado y separado.
¿Vale La Pena Refactorizar Tu Aplicación?
Comencemos por mirar como deberías decidir si tu aplicación es una buena candidata para refactorización.
Aquí hay una lista de métricas y preguntas que usualmente me hago para determinar si mis códigos necesitan o no refactorización.
- Unidades de prueba lentas. las unidades de prueba PORO normalmente corren rápido, con códigos bien aislados, así que las pruebas que corren lento pueden, a menudo, ser un indicador de un mal diseño o responsabilidades sobre-acopladas.
- FAT models or controllers. Un modelo o controlador con más de 200 líneas de código (LOC) es generalmente un buen candidato para refactorizar.
- Base de código excesivamente larga. Si tienes ERB/HTML/HAML con más de 30,000 LOC o código fuente Ruby (sin GEMs ) con más de 50,000 LOC, hay una gran posibilidad de que debas refactorizar.
find app -iname "*.rb" -type f -exec cat {} \;| wc -l
Este comando buscará en todos los archivos con extensión .rb
(archivos ruby) en la carpeta /app, luego imprime el número de líneas.
Por favor, ten en cuenta que este número es solo un aproximado, ya que
las líneas de comentario se incluirán en este total.
Otra opción más precisa e informativa es usar la tarea rake
stats
de Rails, la cual expone un resumen rápido de líneas de código, número
de clases, número de métodos, el ratio de métodos a clases y el ratio de
líneas de código por método:*bundle exec rake stats*
+----------------------+-------+-----+-------+---------+-----+-------+
| Nombre | Líneas | LOC | Clase | Método | M/C | LOC/M |
+----------------------+-------+-----+-------+---------+-----+-------+
| Controladores | 195 | 153 | 6 | 18 | 3 | 6 |
| Helpers | 14 | 13 | 0 | 2 | 0 | 4 |
| Modelos | 120 | 84 | 5 | 12 | 2 | 5 |
| Mailers | 0 | 0 | 0 | 0 | 0 | 0 |
| Javascripts | 45 | 12 | 0 | 3 | 0 | 2 |
| Bibliotecas | 0 | 0 | 0 | 0 | 0 | 0 |
| Controlador specs | 106 | 75 | 0 | 0 | 0 | 0 |
| Helper specs | 15 | 4 | 0 | 0 | 0 | 0 |
| Modelo specs | 238 | 182 | 0 | 0 | 0 | 0 |
| Petición specs | 699 | 489 | 0 | 14 | 0 | 32 |
| Routing specs | 35 | 26 | 0 | 0 | 0 | 0 |
| Vista specs | 5 | 4 | 0 | 0 | 0 | 0 |
+----------------------+-------+-----+-------+---------+-----+-------+
| Total | 1472 |1042 | 11 | 49 | 4 | 19 |
+----------------------+-------+-----+-------+---------+-----+-------+
Código LOC: 262 Prueba LOC: 780 Ratio Código a Prueba: 1:3.0
- ¿Puedo extraer patrones recurrentes en mi base de código?
Separando en Acción
Comencemos con un ejemplo de la vida real.
Imagina que queremos escribir una aplicación que siga el tiempo para
las personas que trotan; en la página principal, el usuario puede ver
los tiempos que se introduzcan.

Cada una de las entradas de tiempo tienen fecha, distancia, duración,
e información adicional relevante del “status” (ej.: clima, tipo de
terreno, etc.), y una velocidad promedio que puede ser calculada cuando
sea necesario.
Necesitamos un reporte que muestre la velocidad promedio y distancia
por semana.
Si la velocidad promedio en la entrada es mayor a la velocidad promedio
en total, notificaremos al usuario a través un SMS (para este ejemplo,
usaremos Nexmo RESTful API para enviar el SMS).
La página principal te permitirá seleccionar la distancia, fecha y
tiempo en que se está trotando, para así crear una entrada similar a
ésta:

También tenemos una página de
estadísticas, la cual es básicamente un reporte semanal que incluye la velocidad promedio y distancia cubierta por semana.
- Puedes ver la muestra online aquí.
El Código
La estructura del directorio de laaplicación se ve similar a esto: ⇒ tree
.
├── assets
│ └── ...
├── controllers
│ ├── application_controller.rb
│ ├── entries_controller.rb
│ └── statistics_controller.rb
├── helpers
│ ├── application_helper.rb
│ ├── entries_helper.rb
│ └── statistics_helper.rb
├── mailers
├── models
│ ├── entry.rb
│ └── user.rb
└── views
├── devise
│ └── ...
├── entries
│ ├── _entry.html.erb
│ ├── _form.html.erb
│ └── index.html.erb
├── layouts
│ └── application.html.erb
└── statistics
└── index.html.erb
No voy a discutir el modelo
Usuario ya que no es nada fuera de lo común, dado que lo estamos usando con Devise para implementar autenticación.En lo referente al modelo
Entrada, contiene la lógica de negocios para nuestra aplicación.Cada
Entrada pertenece a un Usuario.Validamos la presencia de los siguientes atributos para cada entrada
distancia, períodode_tiempo, fecha_hora y estatus.
Cada vez que creamos una entrada, comparamos la velocidad promedio
del usuario con el promedio de todos los usuarios en el sistema, y le
notificamos al usuario vía SMS, usando Nexmo(no discutiremos como se usa la biblioteca de Nexmo, aunque quería demostrar un caso en el que usamos una biblioteca externa).
Nota que la Entrada modelo contiene más que la lógica de negocio sola. También maneja algunas validaciones y llamados.La
entries_controller.rb tiene las acciones CRUD principales (aunque sin actualización). EntriesController#index obtiene las entradas para el usuario actual y ordena los records por fecha de creación, mientras que EntriesController#create crea una nueva entrada. No hay necesidad de discutir lo obvio ni las responsabilidades de EntriesController#destroy :Mientras que
statistics_controller.rb es responsable de calcular el informe semanal, StatisticsController#index obtiene las entradas para el usuario conectado y los agrupa por semana, empleando el método #group_by el cual se encuentra en la clase Enumerable en Rails. Luego, intenta decorar los resultados al usar algunos métodos privados.No discutimos mucho las vistas aquí ya que el código fuente se explica así mismo.
Debajo se encuentra la vista para enlistar las entradas para el usuario conectado (
index.html.erb). Este es el patrón que se usará para mostrar los resultados de la acción índice (método) en el controlador de entradas:Nota que estamos usando
render @entries parciales, para llevar el código compartido a un patrón parcial _entry.html.erb para que así podamos mantener nuestro código DRY y reusable:Lo mismo se aplica a una
_forma parcial. En vez de usar el mismo código con (nuevas y editadas) acciones, creamos una forma parcial reusable:En lo que concierne a la vista de la página de informe semanal,
statistics/index.html.erb muestra algunas estadísticas, e informa sobre las actividades semanales del usuario al agrupar algunas entradas:Y finalmente, el helper para las entradas,
entries_helper.rb, incluye dos helpers readable_time_period y readable_speed los cuales deberían hacer los atributos más fáciles de leer:
Nada muy complicado hasta ahora.
La mayoría de ustedes pueden argumentar que refactorizar esto va en contra del principio KISS y hará el sistema más complicado.
¿Entonces, esta aplicación, de verdad, necesita ser refactorizada?
Absolutamente no, pero lo consideraremos solo con el propósito de muestra.
Después de todo, si observas la siguiente sección y las
características que indican que una aplicación necesita refactorización,
se vuelve obvio que la aplicación en nuestro ejemplo, no es una
candidata válida para refactorización.
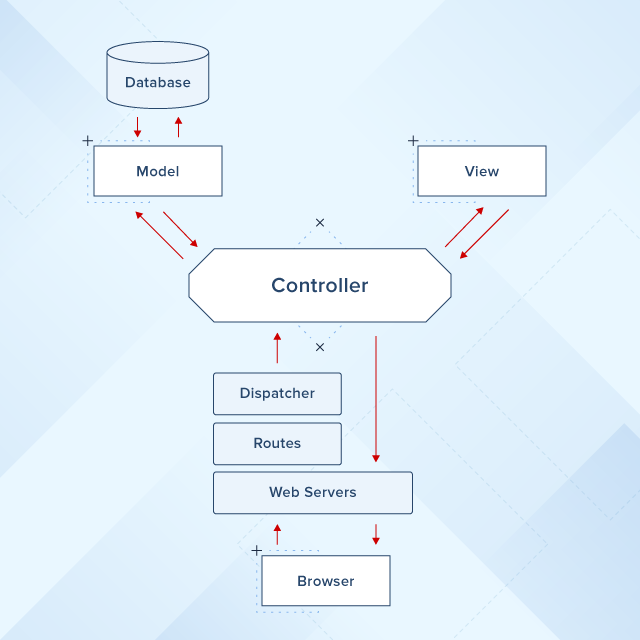
El Ciclo De La Vida
Empecemos por explicar el patrón de estructura MVC en Rails.
Usualmente comienza por el buscador al hacer una petición como
https://www.toptal.com/jogging/show/1.
El servidor web recibe la petición y usa
rutas para definir qué controlador usar.
Los controladores hacen el trabajo de analizar las peticiones de
usuarios, entregas de data, cookies, sesiones, etc., y luego pide al
modelo que obtenga la data.
Los
modelos son clases Ruby que le hablan a la base de
datos, guardan y validan la data, ejecutan la lógica de negocio y hacen
el trabajo pesado. Las vistas son lo que el usuario puede ver: HTML,
CSS, XML, Javascript, JSON.
Si queremos mostrar la secuencia de una petición de ciclo de vida Rails, se vería como esto:

Lo que quiero conseguir es agregar más abstracción, usando POROs y hacer el patrón algo similar a lo siguiente, para las acciones
create/update: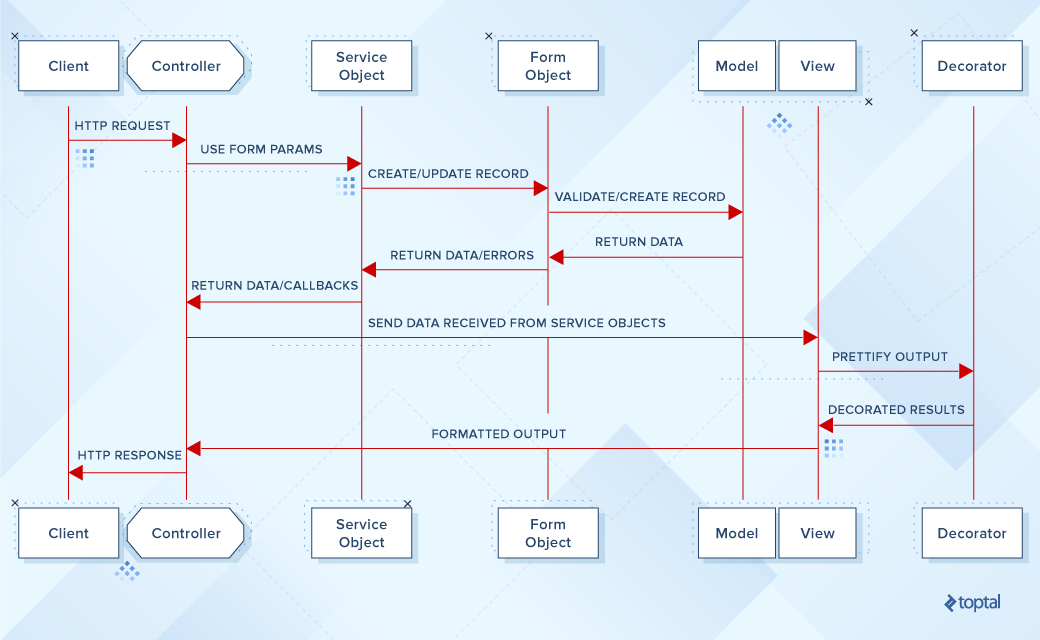
Y algo similar a esto para las acciones
list/show :
Al agregar abstracciones POROs estamos asegurando una separación completa, entre responsabilidades SRP, algo que Rails no domina totalmente.
Directrices
Para alcanzar el nuevo diseño, usaré las directrices que se ven
abajo, pero ten en cuenta que éstas no son reglas que debes seguir al
pie de la letra. Piensa que son directrices flexibles que hacen
refactorizar más fácil.
-
Los modelos ActiveRecord pueden contener asociaciones y constantes, pero nada más. Eso significa que no habrá llamados (usa objetos de servicio y agrega los llamados ahí) y sin validaciones (usa Form objects para incluir nombres y validaciones para el modelo).
-
Mantén a los Controladores como capas delgadas y siempre llama a objetos de Servicio.
Algunos de ustedes se preguntarán ¿por qué usar controladores, si
queremos seguir llamando objetos de servicio para contener la lógica?
Bueno, los controladores son un buen lugar para tener el routing
HTTP, análisis de parámetros, autenticación, negociación de contenidos,
llamar al servicio correcto u objeto editor, atrapar excepciones,
formato de respuestas y regresar el estado de código HTTP correcto.
- Los servicios deberían llamar objetos Query, y no almacenar estado. Usa métodos de instancia no de clase. Deben haber muy pocos métodos públicos guardados con SRP.
-
Queries deberían hacerse con objetos query. Los métodos de objeto Query deben regresar un objeto, un hash o array, pero no una asociación ActiveRecord.
-
Evita usar Helpers, mejor usa decoradores. ¿Por qué? Una dificultad común con helpers en Rails, es que se pueden convertir en un montón de funciones no-OO,
las cuales comparten un nombre de espacio y se sobreponen entre ellas.
Pero es mucho peor, el hecho no de que no se puede usar ningún
polimorfismo con los helpers de Rails — al proveer diferentes
implementaciones para diferentes contextos o tipos, y superación o
sub-clasificación de helpers. Pienso que las clases de helper
en Rails deberían usarse, generalmente, para métodos de utilidad, no
para casos de uso específico; como formatear atributos modelo para
cualquier lógica de presentación. Mantenlos ligeros y fáciles de seguir.
Decoradores/Delegantes mejor.** ¿Por qué? Después de todo, las
preocupaciones parecen ser parte de Rails, y pueden secar (DRY up)
un código cuando se comparte entre múltiples modelos. Sin embargo, el
problema mayor es que las preocupaciones no hacen al objeto modelo más
cohesivo. Solo que el código está mejor organizado. En otras palabras,
no hay un cambio real al API del modelo.
-
Intenta extraer Objetos de Valor de los modelos para mantener tu código más limpio y agrupar atributos relacionados.
- Siempre pasa una variable de instancia por cada vista.
Refactorizar
Antes de empezar quiero discutir algo más. Cuando se comienza la refactorización, usualmente terminas preguntándote: “¿Es una buena refactorización?”
Si sientes que estás haciendo más separación o aislamientos entre
responsabilidades (aunque eso signifique agregar más código y nuevos
archivos) entonces, esto es algo bueno. Después de todo, separar una
aplicación es una muy buena práctica y hace más fácil, para nosotros,
hacer una prueba de unidad apropiada.
No voy a discutir cosas, como mover lógica desde los controladores a
los modelos, ya que supongo que a estás haciendo eso y te sientes cómodo
usando Rails (usualmente Controlador Flaca y modelo FAT).
Con el propósito de mantener este artículo conciso, no voy a discutir
cómo hacer pruebas pero esto no significa que tú no deberías hacer
pruebas.
Por el contrario, deberías empezar siempre con una prueba para asegurarte de que las cosas van bien, antes de avanzar. Esto es algo obligatorio, en especial cuando se hace refactorización.
Luego podemos implementar cambios y asegurarnos de que las pruebas pasen por las partes relevantes del código.
Extraer Objetos De Valor
Primero, ¿qué es un objeto de valor?Martin Fowler explica:
Objeto de Valor es un objeto pequeño, como un objeto de dinero o rango de fechas. Su característica clave es que siguen semánticas de valor, en vez de semánticas referenciales.
En ocasiones, te puedes encontrar con una situación donde un concepto
merece su propia abstracción y donde la igualdad de ésta no se basa en
valores, sino en la identidad. Ejemplos de esto pueden ser: Ruby’s Date,
URI y Pathname. La extracción de un objeto de valor (o modelo de
dominio) es una gran conveniencia.
¿Para qué molestarse?
Una de las grandes ventajas de un objeto de valor, es que ayudan a
obtener una expresividad en tu código. Tu código tendrá una tendencia a
ser más claro, o al menos puede serlo si tienes buenas prácticas en
cuanto a nombres. Ya que el Objeto de Valor es una abstracción, lleva a
códigos más claros y menos errores.

Otra ganancia es la inmutabilidad.
La inmutabilidad de objetos es muy importante. Cuando estamos
almacenando ciertos sets de data, lo cual puede ser usado en un objeto
de valor, usualmente no me gusta que la data sea manipulada.
¿Cuándo es esto útil?
No existe la respuesta perfecta a esta pregunta. Haz lo que sea más
conveniente para ti y lo que tenga más sentido en una situación dada.
Más allá de esto, hay algunas directrices que uso para ayudarme a tomar esa decisión.
Si crees que un grupo de métodos está relacionado, bueno, con objetos
de valor es más caro. Esta expresividad significa que un objeto de
valor, debería representar un set de data distintivo, lo cual puede ser
deducido por tu desarrollador promedio solo con ver el nombre del
objeto.
Los Objetos de Valor deberían seguir ciertas reglas:
- Los Objetos de Valor deberían tener múltiples atributos.
- Los atributos deberían ser inmutables, a través del ciclo de vida del objeto.
- La igualdad es determinada por los atributos del objeto.
En nuestro ejemplo, crearé un objeto de valor
EntryStatus, para abstraer los atributos Entry#status_weather y Entry#status_landform a su propia clase, lo cual se ve de esta manera:
Nota: Esto es solo un PORO (Plain Old Ruby Object), no se hereda de
ActiveRecord::Base.
Hemos definido métodos de lector para nuestros atributos y estamos
asignándolos al inicio. También, usamos una mezcla comparable, para
equiparar objetos usando el método (<=>).
Podemos modificar el modelo
También podemos modificar el método Entry para usar el objeto de valor que hemos creado:EntryController#create para usar el nuevo objeto de valor en concordancia:Extrae Objetos de Servicio
¿Qué es un objeto de Servicio?
El trabajo de un objeto de Servicio es mantener el código durante un
espacio particular de la lógica de negocio. A diferencia del estilo “modelo fat”,
donde un número pequeño de objetos contienen muchos, muchos métodos,
para toda la lógica necesaria, usando objetos de servicio da como
resultado muchas clases, cada una de éstas sirviendo un propósito único.

¿Por qué? ¿Cuáles son los beneficios?
-
Separar. Los Objetos de Servicio te ayudan a conseguir más aislaciones entre los objetos.
-
Visibilidad. Los Objetos de Servicio (Si están
bien nombrados) muestran lo que hace una aplicación. Puedo pasar la
mirada por el directorio de servicios, para ver que capacidades provee
una aplicación.
- Limpia modelos y controladores. Los controladores encienden la petición (params, sesión, cookies) en los argumentos, los pasa al servicio y los redirige o deja dependiendo de la respuesta del servicio. Mientras los modelos solo tratan con asociaciones y persistencia. Extraer código de los controladores/modelos hacia objetos de servicio apoyaría a SRP y separaría más el código. La responsabilidad del modelo sería solo tener que lidiar con asociaciones y guardar/eliminar registros, mientras el objeto de Servicio tendría una sola responsabilidad (SRP). Esto lleva a un mejor diseño y mejores unidades de prueba.
-
DRY y Acepta el cambio.
Yo mantengo objetos de servicio lo más simple y pequeños posible. Yo
compongo objetos de servicio con otros objetos de servicio, y los reúso.
-
Limpia y acelera tu suite de pruebas. Los
servicios son fáciles y rápidos de probar, ya que son objetos Ruby
pequeños con un punto de entrada (el método llamada). Los servicios
complejos se componen con otros servicios, así que puedes separar tus
pruebas fácilmente. También, usar objetos de servicio hace más fácil
recuperar objetos relacionados sin necesidad de cargar el ambiente
completo de rails.
- Rescatable desde cualquier parte. Los objetos de servicio serán llamados, seguramente, desde los controladores al igual que desde objetos de servicio, DelayedJob / Rescue / Sidekiq Jobs, Rake tasks, consola, etc.
Por otro lado, nada es perfecto. Una desventaja de los objetos de
Servicio es que pueden ser un exceso para cada pequeña acción. En estos
casos, puedes terminar complicando y no simplificando tu código.
¿Cuándo deberías extraer Objetos de Servicio?
Aquí tampoco hay una regla fija.
Normalmente, los objetos de Servicio son mejores para sistemas de
medianos a grandes: aquellos con una cantidad decente de lógica, más
allá de las operaciones CRUD estándares.
Así que cuando pienses que un trozo del código no pertenece en el
directorio, en el lugar donde lo ibas a agregar, es buena idea
reconsiderarlo y ver si sería mejor que fuese a un objeto de servicio.
Aquí están algunos indicadores de cuándo usar objetos de Servicio:
- La acción es compleja.
- La acción alcanza múltiples modelos.
- La acción interactúa con un servicio externo.
- La acción no es una preocupación primordial del modelo subrayado.
- Hay múltiples maneras de realizar la acción.
Diseñar la clase para un objeto de servicio es relativamente directo, ya que no necesitas gems especiales, tampoco debes aprender un DLS nuevo, pero si puedes, más o menos, confiar en las habilidades de diseño software que ya posees.
Usualmente, utilizo las siguientes directrices y convenciones para diseñar el objeto de servicio:
- No almacenes el estado del objeto.
- Usa métodos de instancia, no métodos de clase.
- Debe haber muy pocos métodos públicos (preferiblemente uno que apoye *SRP.
- Los métodos deben regresar resultados de objeto ricos, no booleanos.
- Los servicios van debajo del directorio
app/services. Te aconsejo que uses subdirectorios, para dominios lógicas de negocio fuertes. Por ejemplo, el archivoapp/services/report/generate_weekly.rbdefiniráReport::GenerateWeeklymientras queapp/services/report/publish_monthly.rbdefiniráReport::PublishMonthly. - Los servicios comienzan con un verbo (y no terminan en servicio):
ApproveTransaction,SendTestNewsletter,ImportUsersFromCsv. - Los servicios responden al método llamada. Me di cuenta que usar otro verbo lo hace un poco redundante: ApproveTransaction.approve() no se lee bien. También, el método llamada, es el método de facto de lambda, procs, y objetos de método.
Si observas
StatisticsController#index, notarás un grupo de métodos (weeks_to_date_from, weeks_to_date_to, avg_distance, etc.) agrupados al controlador. Eso no es bueno. Considera las ramificaciones, si quieres generar el informe semanal fuera de statistics_controller.
En nuestro caso, vamos a crear
Así que Report::GenerateWeekly y extraigamos el informe de lógica de StatisticsController:StatisticsController#index ahora se ve más limpio:
Al aplicar el patrón del objeto de Servicio, agrupamos código
alrededor de una acción compleja y específica y promovemos la creación
de métodos pequeños y más claros.
Extrae Objetos Query De Los Controladores
¿Qué es un Objeto Query?
Un objeto Query es un PORO, el cual representa una base de
datos de consulta. Puede ser reusada en diferentes lugares de la
aplicación, mientras que, al mismo tiempo, esconde la lógica de
consulta. También provee una buena unidad aislada para pruebas.
Deberías extraer consultas SQL/NoSQL complejas hacia sus propias clases.
Cada objeto Query es responsable de regresar un set de resultados basado en las reglas de criterio/negocio.

En este ejemplo, no tenemos ninguna consulta (query) compleja, así que usar objeto Query no sería eficiente. Sin embargo, con el fin de demostrar, extraeremos la consulta en
Y en Report::GenerateWeekly#call y crearemos generate_entries_query.rb:Report::GenerateWeekly#call, reemplacemos: def call
@user.entries.group_by(&:week).map do |week, entries|
WeeklyReport.new(
...
)
end
end
def call
weekly_grouped_entries = GroupEntriesQuery.new(@user).call
weekly_grouped_entries.map do |week, entries|
WeeklyReport.new(
...
)
end
end
El patrón de objeto query (consulta) ayuda a mantener la
lógica de tu modelo estrictamente relacionada a un comportamiento de
clase, mientras que mantiene tus controladores flacas. Debido a que no
son más que plain old Ruby classes, los objetos query no necesitan heredar de
ActiveRecord::Base, y deberían ser responsables por nada más que la ejecución de consultas.Extrae Crear Entrada A Un Objeto de Servicio
Ahora, vamos a extraer la lógica de crear una nueva entrada a un nuevo objeto de servicio. Vamos a usar la convención y creemosCreateEntry:Y ahora nuestro
EntriesController#create es de la siguiente manera: def create
begin
CreateEntry.new(current_user, entry_params).call
flash[:notice] = 'Entry was successfully created.'
rescue Exception => e
flash[:error] = e.message
end
redirect_to root_path
end
Más Validaciones A Un Objeto De Forma
Ahora las cosas comienzan a ponerse más interesantes.
Recuerda que en nuestras directrices acordamos que queríamos que los
modelos tuvieran asociaciones y constantes, pero nada más (ni
validaciones ni llamados). Así que empecemos por remover los llamados y
usa un objeto de Forma en su lugar.
Un objeto de Forma es un PORO (Plain Old Ruby Object). Toma el mando
del controlador/objeto de servicio cuando necesite hablar con la base de
datos.
¿Por qué usar objetos de Forma?
Cuando necesites refactorizar tu aplicación, siempre es buena idea tener en mente, la responsabilidad única principal (SRP).
SRP te ayuda a tomar mejores decisiones de diseño, en cuanto a la responsabilidad que debe tener una clase.
Tu modelo de mesa de base de datos (un modelo ActiveRecord en el
contexto de Rails), por ejemplo, representa un record de la base de
datos único en código, así que no hay razón para que esté preocupado con
nada que haga tu usuario.
Aquí es donde entra el objeto de Forma.
Un objeto de Forma es responsable de representar una forma en tu
aplicación. Así que cada campo de entrada puede ser tratado como un
atributo en la clase. Puede validar que esos atributos cumplen algunas
reglas de validación, y puede pasar la data “limpia” a donde debe ir
(ej., tu modelo de base de datos o tal vez tu constructor de búsqueda de
consultas).
¿Cuándo deberías usar un objeto de Forma?
- Cuando quieras extraer las validaciones de los modelos Rails.
- Cuando múltiples modelos pueden ser actualizados por una sola forma de entrega, deberías crear un objeto de Forma.
¿Cómo crear un objeto de Forma?
- Crea una clase simple Ruby.
- Incluye
ActiveModel::Model(en Rails 3, tienes que incluir Nombre, Conversión y Validación, en su lugar). - Empieza a usar tu nueva clase de forma, como si fuera un modelo regular de ActiveRecord, donde la mayor diferencia es que no puedes continuar con la data almacenada en este objeto.
entry_form.rb lo cual se ve así:Y modificaremos
CreateEntry para comenzar a usar el objeto de Formato EntryForm: class CreateEntry
......
......
def call
@entry_form = ::EntryForm.new(@params)
if @entry_form.valid?
....
else
....
end
end
end
Nota: Algunos de ustedes dirán que no hay
necesidad de acceder al objeto de Forma desde el objeto de Servicio y
que podemos llamar al objeto de Forma directamente desde el controlador,
lo cual es un argumento válido. Sin embargo, preferiría tener un flujo
claro, por eso siempre llamo al objeto de Forma desde objeto de
Servicio.
Mueve los Llamados al Objeto de Servicio.
Como acordamos anteriormente, no queremos que nuestros modelos
contengan validaciones y llamados. Extrajimos las validaciones usando
objetos de Forma. Pero todavía estamos usando algunos llamados (
after_create en modelo Entry compare_speed_and_notify_user).¿Por qué queremos remover los llamados de los modelos?
Desarrolladores Rails
usualmente comienzan a notar un dolor con los llamados, durante las
pruebas. Si no estás haciendo pruebas con tus modelos ActiveRecord,
comenzarás a notar el dolor después, mientras crece tu aplicación y
mientras se necesite más lógica para llamar o evitar los llamados.
después_* los llamados son usados primordialmente en relación a guardar o continuar con el objeto.
Una vez que el objeto es guardado, el propósito (ej. responsabilidad)
del objeto ha sido cumplido. Así que, si todavía vemos llamados siendo
invocados, después de que el objeto ha sido guardado, estos
probablemente son llamados que buscan salir del área de responsabilidad
de objetos, y ahí es cuando encontramos problemas.
En nuestro caso, estamos enviando un SMS al usuario, lo que no está relacionado con el dominio de Entrada.
Una manera simple de resolver el problema es, mover el llamado al
objeto de servicio relacionado. Después de todo, enviar un SMS para el
usuario correspondiente está relacionado al Objeto de Servicio
CreateEntry y no al modelo Entrada, como tal.
Al hacer esto, ya no tenemos que apagar, el método
compare_speed_and_notify_user
en nuestras pruebas. Hemos hecho que esto sea un asunto sencillo, el
crear una entrada sin que sea necesario enviar un SMS y estamos
siguiendo un buen diseño de Objeto Orientado, al asegurarnos de que
nuestras clases tengan una responsabilidad única (SRP).
Así que ahora
CreateEntry es algo similar a esto:Usa Decoradores En Vez De Helpers
Aunque podemos fácilmente usar la colección Draper de modelos de vista y decoradores, me quedo con PORO, por este artículo, como lo he estado haciendo hasta ahora.
Lo que necesito es una clase que llame métodos al objeto decorado.
Puedo usar
method_missing para implementar eso, pero usaré la biblioteca estándar de Ruby, SimpleDelegator. El siguiente código muestra cómo usar SimpleDelegator para implementar nuestro decorador base: % app/decorators/base_decorator.rb
require 'delegate'
class BaseDecorator < SimpleDelegator
def initialize(base, view_context)
super(base)
@object = base
@view_context = view_context
end
private
def self.decorates(name)
define_method(name) do
@object
end
end
def _h
@view_context
end
end
_h?
Este método actúa como un proxy para contexto de vista. Por defecto,
el contexto de vista es una instancia de una clase vista, siendo ésta
ActionView::Base. Puedes acceder a los helpers de vistas de la siguiente manera: _h.content_tag :div, 'my-div', class: 'my-class'
decorado a ApplicationHelper: module ApplicationHelper
# .....
def decorate(object, klass = nil)
klass ||= "#{object.class}Decorator".constantize
decorator = klass.new(object, self)
yield decorator if block_given?
decorator
end
# .....
end
EntriesHelper a los decoradores: # app/decorators/entry_decorator.rb
class EntryDecorator < BaseDecorator
decorates :entry
def readable_time_period
mins = entry.time_period
return Time.at(60 * mins).utc.strftime('%M Mins').html_safe if mins < 60
Time.at(60 * mins).utc.strftime('%H Hour %M Mins').html_safe
end
def readable_speed
"#{sprintf('%0.2f', entry.speed)} Km/H".html_safe
end
end
readable_time_period y readable_speed de la siguiente forma: # app/views/entries/_entry.html.erb
- <%= readable_speed(entry) %> </td>
+ <%= decorate(entry).readable_speed %> >
- <%= readable_time_period(entry) %></td>
+ <%= decorate(entry).readable_time_period %> >
Estructura Después De Refactorizar
Terminamos con más archivos, pero eso no es necesariamente algo malo
(y recuerda esto, desde el comienzo, estábamos conscientes de que este
ejemplo era con fines demostrativos y no era necesariamente un buen caso de uso para refactorización):
app
├── assets
│ └── ...
├── controllers
│ ├── application_controller.rb
│ ├── entries_controller.rb
│ └── statistics_controller.rb
├── decorators
│ ├── base_decorator.rb
│ └── entry_decorator.rb
├── forms
│ └── entry_form.rb
├── helpers
│ └── application_helper.rb
├── mailers
├── models
│ ├── entry.rb
│ ├── entry_status.rb
│ └── user.rb
├── queries
│ └── group_entries_query.rb
├── services
│ ├── create_entry.rb
│ └── report
│ └── generate_weekly.rb
└── views
├── devise
│ └── ..
├── entries
│ ├── _entry.html.erb
│ ├── _form.html.erb
│ └── index.html.erb
├── layouts
│ └── application.html.erb
└── statistics
└── index.html.erb
Conclusión
Aunque nos enfocamos en Rails en este blog post, RoR (Ruby on Rails)
no es una dependencia de los objetos de servicio ni de otros POROs.
Puedes usar este enfoque con cualquier framework web, móvil o aplicación de consola.
Al usar MVC como arquitectura, todo se mantiene junto y te
hace ir más lento porque la mayoría de los cambios tienen un impacto en
otras partes de la aplicación. También te obliga a pensar donde poner
algunas lógicas de negocio – ¿debería ir en el modelo, el controlador o
la vista?
Al usar un simple PORO, hemos movido la lógica de negocio a los modelos o servicios, que no heredan de
ActiveRecord, lo cual ya es una ganancia, sin mencionar que tenemos un código más claro, lo cual apoya SRP y pruebas de unidades más rápidas.
Una arquitectura limpia intenta poner las casillas de uso en el
centro/parte superior de tu estructura para que veas fácilmente lo que
hace tu aplicación. También facilita la adopción de cambios, porque es
más modular y aislado.
Espero haber demostrado como al Plain Old Ruby Objects y más abstracciones, separa preocupaciones, simplifica pruebas y ayuda a producir código limpio y fácil de mantener.

No hay comentarios:
Publicar un comentario
Te agradezco tus comentarios. Te esperamos de vuelta.